
はじめに
セキュリティエンジニアの齋藤ことazaraです。今回は、不可思議なContent-Typeの値と、クラウド時代でのセキュリティリスクについてお話しします。 本ブログは、2024 年 3 月 30 日に開催された BSides Tokyo で登壇した際の発表について、まとめたものです。 また、ブログ資料化にあたり、Content-Type の動作や仕様にフォーカスした形で再編を行い、登壇時に口頭で補足した内容の追記、必要に応じた補足を行なっています。
また、本ブログで解説をする BSides Tokyoでの発表のもう一つの題である、オブジェクトストレージについては、以下のブログから確認をすることが可能ですので、ご覧ください。
なぜ今、この問題を取り上げるのか?
従来のファイルアップロードにおいて、Content-Type の値を任意の値に設定することは、特段自身で実装を行わなければ、難しいものでした。しかし、近年のクラウド時代においては、このような状況が変化したともいえます。 例えば、クラウドストレージの一つである、S3互換のオブジェクトストレージにおいては、ファイルのアップロード時にメタデータと呼ばれるデータに関連する情報を付与することが可能になりました。その中には、ファイルがどのようなものかを指定するために、Content-Type という情報を指定することができ、その値はアップロード時に指定することが可能になります。この、Content-Type の値は、ファイルの取得時にレスポンスヘッダーとして返却されるため、ブラウザやクライアントアプリケーションにおいて、そのファイルの種類を判別するために利用されます。
この仕様を利用することで、現代においては、Content-Type を任意の値に設定することが可能になりました。
では、このContent-Typeの値を任意に設定できることによって、どのようなリスクが発生するのでしょうか?そのリスクについて、理解を深めることを目的としています。
概要
Content-Type に起因する攻撃といえば、クライアントサイドでの事象として IE の時代には、Mime Sniffingや UTF-7の解釈に起因するXSSなどに代表される文字コードと掛け合わせることで、発生する XSS が存在していました。 これら、攻撃は年を重ねるごとに、対策が講じられ、そのリスクは低減されてきました。しかし、クラウド時代においては、ファイルのアップロードにおいて、S3互換の登場でContent-Typeの値を任意に設定することが可能になりました。このことにより、従来の攻撃手法を利用することで、新たなリスクや過去に栄え、今には発生しないと考えられていた攻撃が発生する可能性があります。
例えば、Content-Type の値をimage/png, text/htmlと指定することで、画像ファイルであると認識されることが期待されるファイルを、HTML として解釈されることで、XSS 攻撃を行うことが可能になります。
他にも、image /pngのように、スペースを含む値を指定することで、Content-Type として認識できない値を設定することが可能となり、ブラウザのMIME Sniffによる攻撃を行うことが可能になります。
本ブログでは、このような不可思議なContent-Typeの値を利用した攻撃について、その原理やリスク、対策についてお話しします。
- はじめに
- なぜ今、この問題を取り上げるのか?
- 概要
- ファイルのアップロードの変化について
- Content-Typeの不可思議な値
- RFC による定義
- WHATWG による定義
- 双方の差分によって発生する課題
- ブラウザの挙動
- アップロードに用いるContent-Typeの Validation Bypass への悪用
- 対策
- まとめ
- お知らせ
- 参考文献
ファイルのアップロードの変化について
クラウドシフトをはじめとした、アプリケーションインフラの変化により、ファイルのアップロード方法も変化してきました。従来のファイルアップロードでは、ファイルのアップロード時に、ファイルの種類を判別するために、ファイルの拡張子やファイルの先頭バイトを利用して、ファイルの種類を判別していました。しかし、クラウド時代においては、ファイルのアップロード時に、ファイルの種類を指定するためのメタデータを付与することが可能になりました。その中には、ファイルの種類を指定するためのContent-Typeという情報を指定することができ、その値はアップロード時に指定することが可能になります。このContent-Typeの値は、ファイルの取得時にレスポンスヘッダーとして返却されるため、ブラウザやクライアントアプリケーションにおいて、そのファイルの種類を判別するために利用されます。
このContent-Typeの値を任意に設定することが可能になったことで、ブラウザでレンダリングされるファイルの種類を任意に指定することが可能になりました。このことにより、従来の攻撃経路とは異なる形で、XSS などのクライアントを標的とした攻撃を引き起こすことが可能になりました。


Content-Typeの不可思議な値
先に例示したimage/png, text/htmlのようなContent-Typeの値を指定することで、本来画像ファイルであると認識されることが期待されるファイルを、ブラウザなどのクライアントにHTMLとして解釈させることで、XSS 攻撃を行うことが可能になります。
このようなContent-Typeの値は仕様や実際の動作において、どこでどのように解釈されるのでしょうか?
本章では、これら不可思議な値がブラウザ側でHTMLなどに解釈される原因を、仕様を把握し、原理を理解することを目的としています。

RFC による定義
まずはじめに、Content-Type を構成する要素について、RFC による定義を確認します。 現代の Semantics を確認する前に、HTTP/1.1 の Semantics において定義されるContent-Typeについて確認します。

主に RFC 7231 において、Content-Type に関する定義が行われています。その中で、Content-Type は、type "/" subtype *(";" parameter)という形式で定義されています。この形式に従い、image/pngのような値がContent-Typeとして設定されることが期待されます。
また、Content-Type においては、typeとsubtypeの値は、それぞれtokenとして定義されています。tokenとは、RFC 7231 において、tokenは、1*<any CHAR except CTLs or separators>と定義されています。このため、image/pngのような値は、imageとpngの 2 つのtokenから構成されることが期待されます。
このようなContent-Typeの定義により、image/pngのような単一での値がContent-Typeとして設定されることが期待されます。
次に Header Field Definitions において、Header Field の定義について確認します。
RFC 7231 では、Header Field の定義について、以下のように記載されています。
RFC 7231 HTTP/1.1: Semantics and Content
8.3.1. Considerations for New Header Fields
Whether the field is a single value or whether it can be a list (delimited by commas; see Section 3.2 of [RFC7230]).
If it does not use the list syntax, document how to treat messages where the field occurs multiple times (a sensible default would be to ignore the field, but this might not always be the right choice).
Note that intermediaries and software libraries might combine multiple header field instances into a single one, despite the field's definition not allowing the list syntax. A robust format enables recipients to discover these situations (good example: "Content-Type", as the comma can only appear inside quoted strings; bad example: "Location", as a comma can occur inside a URI).
Good example として、Content-Type の例が記載されており、この例によると"で囲まれた場合に限って、,が許容されると記載されています。一方、Bad example として、Location が記載されており、こちらは、URI において,が許容されていませんでした。

では、なぜ,がダブルクォートで囲まれた場合にのみ許容されるのでしょうか?そして、もし,が許容される場合、どのように解釈されるのでしょうか?

その答えは、RFC8941 の Structured Field Values for HTTP に記載されています。Structured Field Values for HTTP は、HTTP ヘッダーの値を構造化するための RFC であり、この仕様に基づくと、,は通常 List 形式において区切り文字として利用されることが記載されています。
そのため、先のContent-Typeの例において、,がダブルクォートで囲まれていない場合、,は List 形式において区切り文字として解釈され、image/pngとtext/htmlの 2 つのContent-Typeが存在すると解釈される可能性あります。


では、これらの定義が最新の定義ではどのようになっているのか確認してみましょう。 最新の定義は、RFC9110 において定義されており、この定義においては、HTTPS Semantics におけるContent-Typeの定義が行われています。
一読してみると、RFC 7231 において定義されていたContent-Typeの定義が、ほぼそのまま引き継がれていることが確認できます。

また、同時に、Token の定義においては、特定の文字列に関して特殊な扱いが行われていることが確認できます。

RFC 9110 HTTP Semantics 5.6.2. Tokens
Many HTTP field values are defined using common syntax components, separated by whitespace or specific delimiting characters. Delimiters are chosen from the set of US-ASCII visual characters not allowed in a token (DQUOTE and "(),/:;<=>?@[\]{}").
ここまでで、RFC においての定義では、Content-Type が明示的に複数の値を取り扱うとした表記はなく、あくまで、単一の値についての定義が行われていることが確認できます。
WHATWG による定義
次に、WHATWG におけるContent-Typeの定義について確認します。
WHATWG においては、Content-Type の定義は Fetch Standard において行われており、その中で、Content-Type は、type "/" subtype *( ";" parameter )という形式で定義されています。
また、同時に,がダブルクォートで囲まれていない場合、,は List 形式において区切り文字として解釈されるとの記載もあり、先の章で例示したimage/png, text/htmlのような値の場合、image/pngとtext/htmlの 2 つのContent-Typeが存在すると解釈されるとされ、最後に指定されたContent-Typeが最終的に解釈に用いられるとされています。
※ただし、ブラウザによっては、この挙動が異なることがあり、最終的に解釈されるContent-Typeの値が有効な場合にのみ、その値が用いられるブラウザと、最後のContent-Typeが解釈不可能でも用いられるブラウザが存在します。
双方の差分によって発生する課題
このように、RFC と WHATWG において、Content-Type の定義については、ほぼ同様の定義が行われています。しかし、その挙動については、若干の差異が存在しています。その最たる例が、,がダブルクォートで囲まれていない場合、,は List 形式において区切り文字として解釈されるという点です。
多くのブラウザにおいては、WHATWG の定義に従い、,がダブルクォートで囲まれていない場合、,は List 形式において区切り文字として解釈され、最後に指定されたContent-Typeが最終的に解釈に用いられます。一方で、OSSなどのサーバーサイドの実装においては、RFC に従い、,がダブルクォートで囲まれていない場合、定義がなされていないため、,は List 形式において区切り文字として解釈されず、単一のContent-Typeとして解釈されることがあります。

ブラウザの挙動
Multiple Value Content-Type
先の WHATWG の定義によると、image/png, text/htmlのような値の場合、image/pngとtext/htmlの 2 つのContent-Typeが存在すると解釈されます。そして、ブラウザにおいて最終的に解釈に用いられるも値は、text/htmlであり、対応するレンダリング処理を行います。
動かして実験してみる
image/png, text/htmlを設定した HTTP レスポンスの検証 PoC を用意したので、実際にブラウザを用いて確認してみましょう。
実際に、以下の PoC を起動し、ブラウザを用いてncで作成され、localhostの18080番ポートにホストされた簡易HTTPサーバーにアクセスすると、一つ目は、image/pngとして表示されるはずのファイルが、二つ目は、image/pngとして表示されるように見えるファイルが、text/htmlとして表示されることが確認できます。
PNG_HEADER="iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAAAAAA6fptVAAAACklEQVQIHWP4DwABAQEANl9ngAAAAABJRU5ErkJggg==" # `image/png`を設定した HTTP レスポンスを返却する PoC while true; do ( \ echo "HTTP/1.0 200 Ok"; echo "Content-Type: image/png"; echo; echo "$(echo $PNG_HEADER | base64 -d)\n<h1>hello world</h1>\n" \ ) \ | nc -l 18080; [ $? != 0 ] && break; done # `image/png, text/html`を設定した HTTP レスポンスを返却する PoC while true; do ( \ echo "HTTP/1.0 200 Ok"; echo "Content-Type: image/png, text/html"; echo; echo "$(echo $PNG_HEADER | base64 -d)\n<h1>hello world</h1>\n" \ ) \ | nc -l 18080; [ $? != 0 ] && break; done
破損したContent-Typeと Sniffing
先の仕様では、 "正しい表現" とは何なのかについて定義されていました。一方で、これから逸脱をしたContent-Typeの値を指定した場合、ブラウザによっては、従来の挙動とは異なる挙動を示すことがあります。
多くの解釈不可能、もしくは破損したContent-Typeの値を指定した場合に、ブラウザがMIME Sniffを行わず、ファイルのダウンロードを促す挙動を示すことがあります。
例えばimage/x!のような定義をされていないContent-Typeを指定した場合、ブラウザではレンダリング等の処理を行わず、ファイルのダウンロードを促す挙動を示します。
# `image/x`を設定した HTTP レスポンスを返却する PoC while true; do ( \ echo "HTTP/1.0 200 Ok"; echo "Content-Type: image/x\\e3rf!"; echo; echo "<h1>hello world</h1>\n" \ ) \ | nc -l 18080; [ $? != 0 ] && break; done
ただ、例外も存在しています。例えば、MimeType における type が破損している場合です。
image /xやimage\(text/pngのようなContent-Typeとしては解釈を行えない値を指定した場合、ブラウザでは Mime Type の Sniffing を行い、ファイルの種類を判別しようとします。このような場合、ファイルの種類を判別するために、ファイルの先頭バイトを用いて、ファイルの種類を判別することがあり、下記の PoC のようなレスポンスの場合は、HTML として解釈され、ブラウザ上でレンダリングされます。
# `image/x`を設定した HTTP レスポンスを返却する PoC while true; do ( \ echo "HTTP/1.0 200 Ok"; echo "Content-Type: image\(text/png"; echo; echo "<h1>hello world</h1>\n" \ ) \ | nc -l 18080; [ $? != 0 ] && break; done
従来のファイル配信やページの配信において、Content-Type が任意の破損した値を指定して行うことは少なく、そのリスクは低いとされていました。しかし、クラウド時代においては、ファイルのアップロードにおいて、Content-Type の値を任意に設定することが可能になりました。このことにより、従来の攻撃経路とは異なる形で、XSS などのクライアントを標的とした攻撃を引き起こすことが可能になりました。
アップロードに用いるContent-Typeの Validation Bypass への悪用
先に述べたブラウザの挙動により、image/png, text/htmlやimage /xのようなContent-Typeの値を指定することで、意図しない形で HTML としてブラウザに解釈させることが可能になったというのは、セキュリティリサーチャーにとっては、面白い切り口であるといえます。
例えば、筆者が見つけたものとして、CVE-2023-49090 および CVE-2024-29034 という一連のファイルアップロードに関連する脆弱性が存在していました。これらの脆弱性は、CarrierWave という Ruby のメジャーなファイルアップロードライブラリの、Content-Type の検証を行うコードで発見されました。
CarrierWave は、ライブラリの利用者が許可したいContent-Typeの値を指定することが可能であり、その値が許可されているかどうかを検証するためのコードが存在しています。

このコードは内部実装的に、次のような検証用のメソッドを呼び出し、動的にContent-Typeの値を検証する正規表現を生成します。

このような実装の場合、利用者は完全一致になるように正規表現形式で許可されるべきContent-Typeを示す必要がありますが、実際のユースケースとしては、そのような指定方法は多く存在しませんでした。
最も多い実装例としては下記のように PNG ファイルであればimage/pngという値を許可するというもので、結果的に部分一致な正規表現が生成され、text/html;image/pngやimage/png, text/htmlのような値を指定することで、HTML ファイルをアップロードすることが可能になります。

余談ではありますが、この脆弱性を修正する段階で、この調査を完遂できておらず、誤った修正を例示してしまい、結果として 2 つの CVE が発行されるという事態になりました。閑話休題。
最終的な修正としては、以下のようにMarcel::MimeType.forを用いて、ユーザーの入力、もしくは機械的に生成されたContent-Typeの値を安全な形に変換することで、この脆弱性を解消することができました。

このような形で、現実世界においても、このようなContent-Typeの不可思議な表記と動きを用いることで、ファイルアップロードにおけるContent-Typeの Validation Bypass が悪用される可能となりました。
対策
最後に対策についてお話しします。
Validation 時の検証における対策
Content-type をはじめとする Validation を部分一致や、正規表現などで行う場合、その検証の厳密さによって、攻撃を受けるリスクが変わります。そのため、検証の際には、完全一致もしくは、RFC9110 などに準拠した検証を行うことが望ましいです。
また、Validation 後の処理においても、無害化されたContent-Typeの値を用いることが望ましいです。例えば、Marcel::MimeType.forを用いることで、ユーザーの入力、もしくは機械的に生成されたContent-Typeの値を安全な形に変換することができます。
X-Content-Type-Options による対策
現代においても、ブラウザのMime Sniffによる攻撃が現実的であることは、先に述べている通りであり、そのリスクを低減するためには、X-Content-Type-Options ヘッダーを用いることが望ましいです。
X-Content-Type-Options ヘッダーは、ブラウザのMime Sniffに関する動作を指示するヘッダーでであり、nosniffを指定することで、ブラウザはMime Sniffを行わず、指定されたmime type、または解釈できなかった際はtext/plainとして解釈をします。
nosniffを指定した場合の検証は下記のコードを用いることが可能です。
while true; do ( \ echo "HTTP/1.0 200 Ok"; echo "Content-Type: image\(text/png"; echo "X-Content-Type-Options: nosniff"; echo; echo "<h1>hello world</h1>\n" \ ) \ | nc -l 18080; [ $? != 0 ] && break; done
実際にアクセスを行うと、ブラウザは Mime Sniffを行わず、ファイルレンダリングがtext/plainとして行われることが確認できます。
ファイルの配信を行うドメインやオリジンを分離する
最も望ましい対策として、親のドメインを含め完全に分離がなされたファイル配信用のサンドボックスドメインを用意することが挙げられます。このような形で、ファイルの配信を行うドメインやオリジンを分離することで、XSS などが発生した場合でも、攻撃者が悪用することが難しくなります。
例:
Main Domain: example.com File Delivery Domain: file.example.test
まとめ
本ブログでは、不可思議なContent-Typeの値と、クラウド時代でのセキュリティリスクについてお話しました。
Content-Type に起因する攻撃といえば、クライアントサイドでの事象として IE の時代には、Mime Sniffingや UTF-7 などに代表される文字コードと掛け合わせることで、発生する XSS が存在していました。これら、攻撃は年を重ねるごとに、対策が講じられ、そのリスクは低減されてきました。しかし、クラウド時代においては、ファイルのアップロードにおいて、S3互換のオブジェクトストレージが登場したことでContent-Typeの値を任意に設定することが可能になりました。このことにより、従来の攻撃手法を利用することで、新たなリスクや過去に栄え、今には発生しないと考えられていた攻撃が発生する可能性があります。
例えば、Content-Type の値をimage/png, text/htmlと指定することで、画像ファイルであると認識されることが期待されるファイルを、HTML として解釈されることで、XSS 攻撃を行うことが可能になります。
このような不可思議なContent-Typeの値を利用した攻撃について、その原理やリスク、対策についてお話ししました。
最後に、対策についてお話ししました。Validation 時の検証における対策、X-Content-Type-Options による対策、ファイルの配信を行うドメインやオリジンを分離することで、このような攻撃を防ぐことが可能です。
お知らせ
Flatt Security ではWebアプリケーションをはじめとする、様々なプロダクトへのセキュリティ診断サービスを提供しています。仕様・実装に不安のある方はぜひお気軽にお問い合わせください。
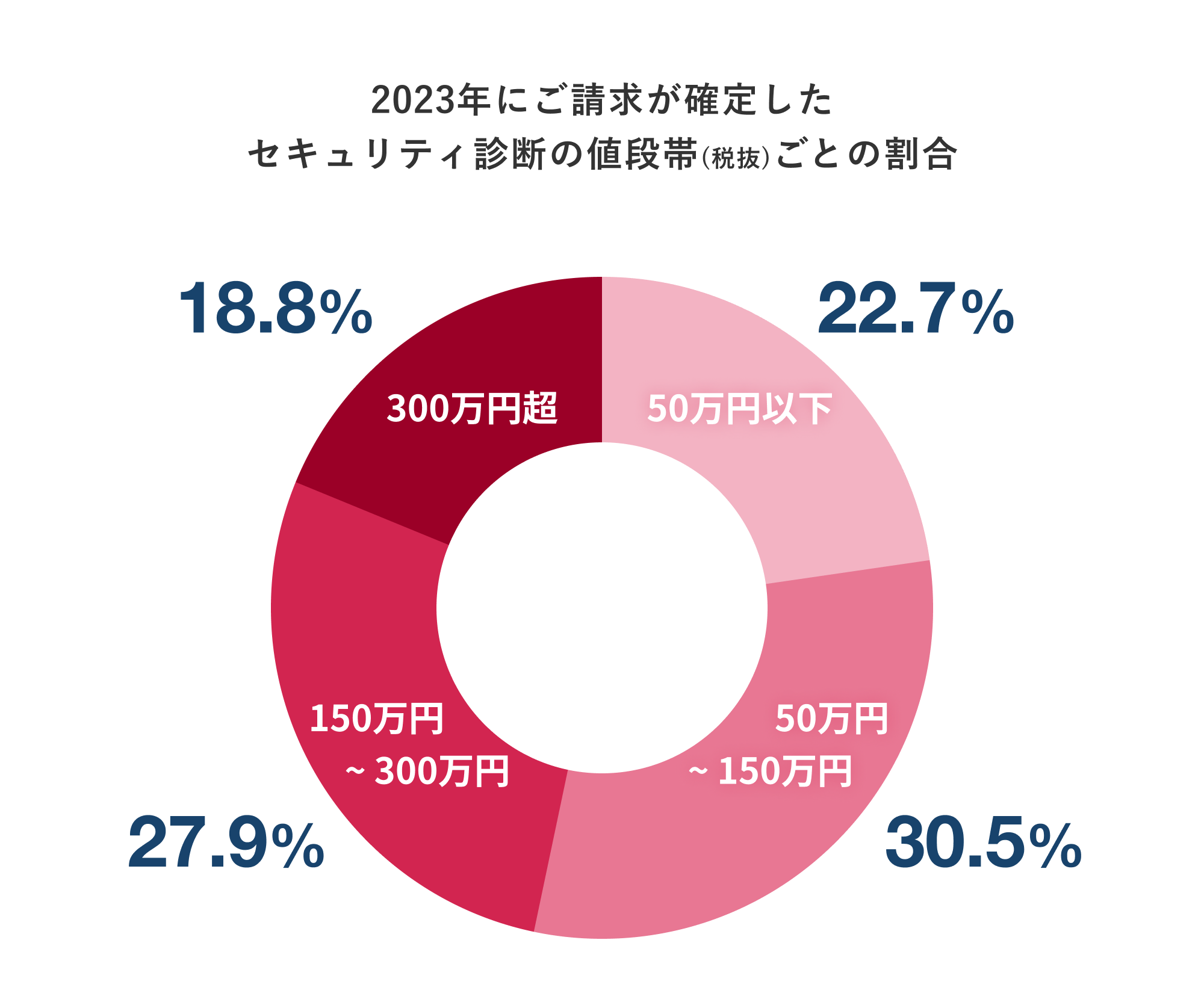
上記のデータが示すように、診断は幅広いご予算帯に応じて実施が可能です。ご興味のある方向けに下記バナーより料金に関する資料もダウンロード可能です。

また、Flatt Security はセキュリティに関する様々な発信を行っています。 最新情報を見逃さないよう、公式X のフォローをぜひお願いします!
では、ここまでお読みいただきありがとうございました。